Mail: zhihazhan2-c [at] my [dot] cityu [dot] edu [dot] hk
About Me
I am currently serving as the Algorithm Team Lead at TopXGun (Nanjing)
Robotics Co., Ltd. in China, where I lead a small team focusing on SLAM, Perception, 3D Reconstruction,
and Coverage Path Planning for UAV autopilot systems.
Previously, I received an M.Sc. in Multimedia Information Technology from the City University of Hong Kong, supervised by Prof. Ho
Man Chan.
My research interests lie in Spatial Intelligence and Field Robotics, particularly in the following
areas:
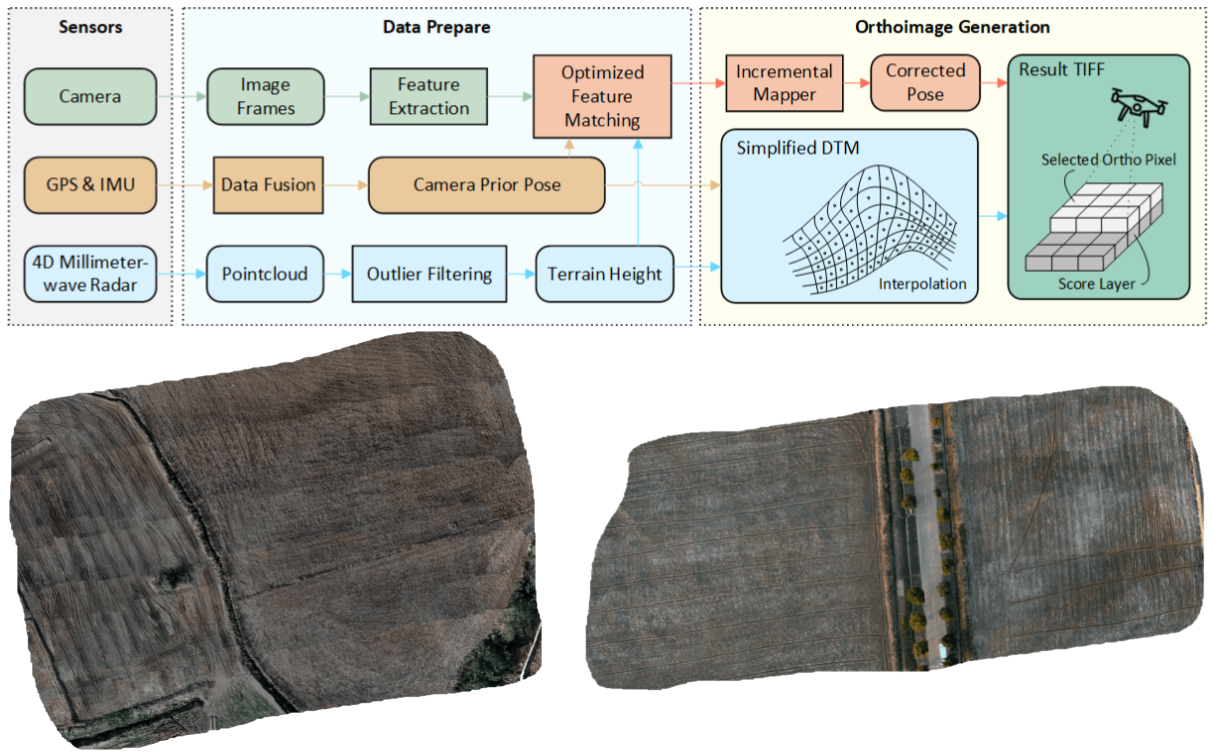
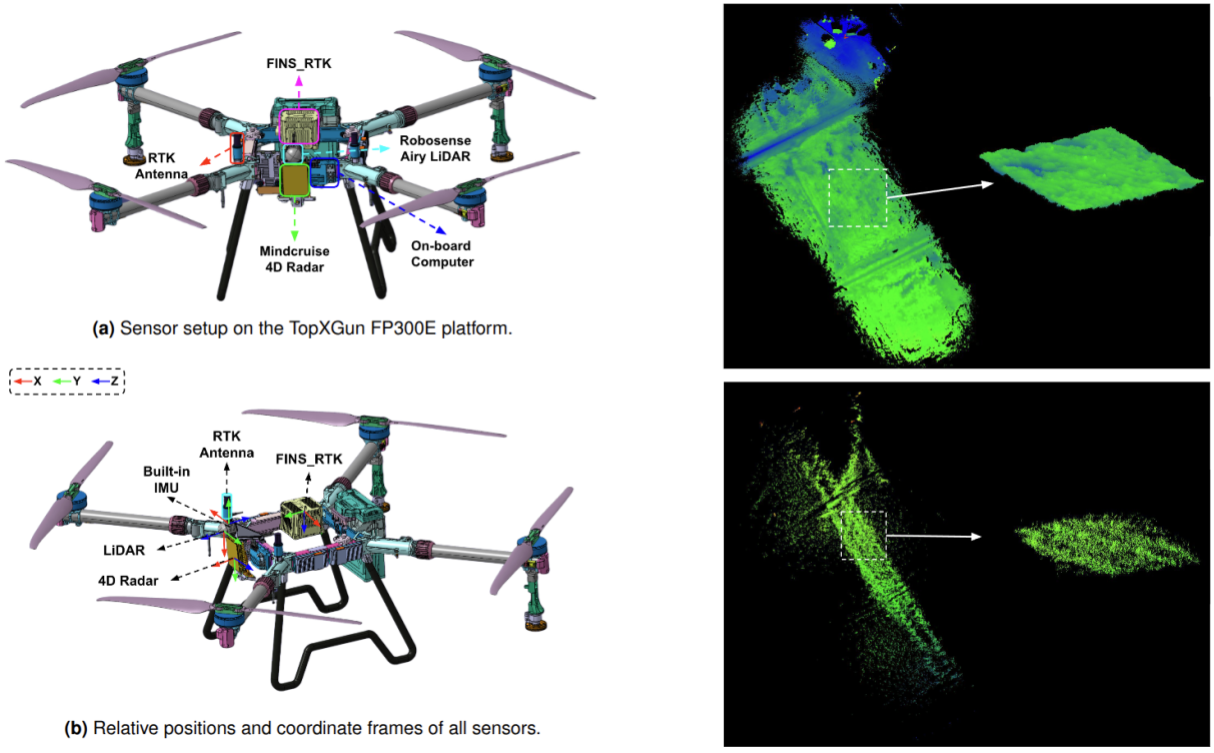
Multi-Sensor Fusion SLAM and Structure-from-Motion (SfM).
Embodied Spatial AI, such as Gaussian Splatting (GS) and VGGT.
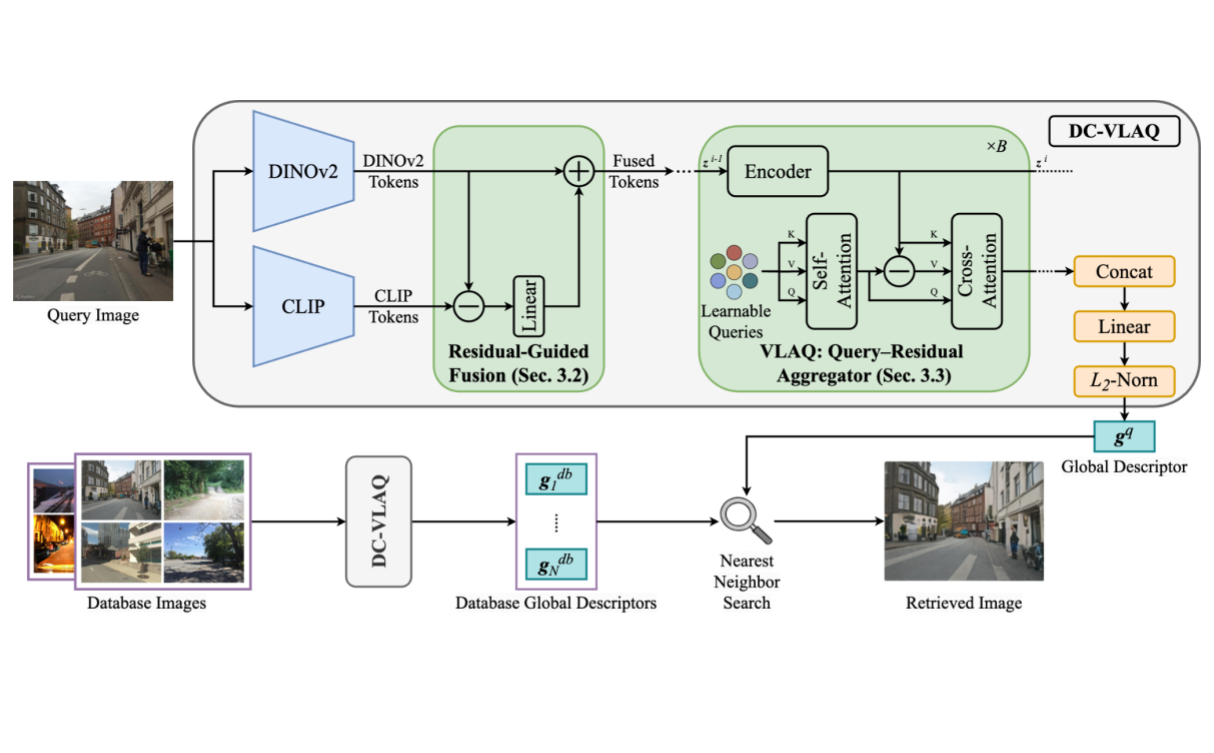
Multi-Modal Place Recognition (PR).
News
Jun, 2026 - One paper is accepted by IROS 2026.
Jun, 2026 - One paper is accepted by Signal, Image and Video Processing.